摘要 (TL;DR)
智能体(Agent)需要上下文来执行任务。上下文工程(Context Engineering)是在智能体运行轨迹的每一步中,用恰到好处的信息填充其上下文窗口的艺术与科学。在本文中,我们通过回顾各种流行的智能体和论文,剖析了一些常见的上下文工程策略——写入(write)、选择(select)、压缩(compress)和隔离(isolate)。然后,我们将解释 LangGraph 是如何被设计来支持这些策略的!
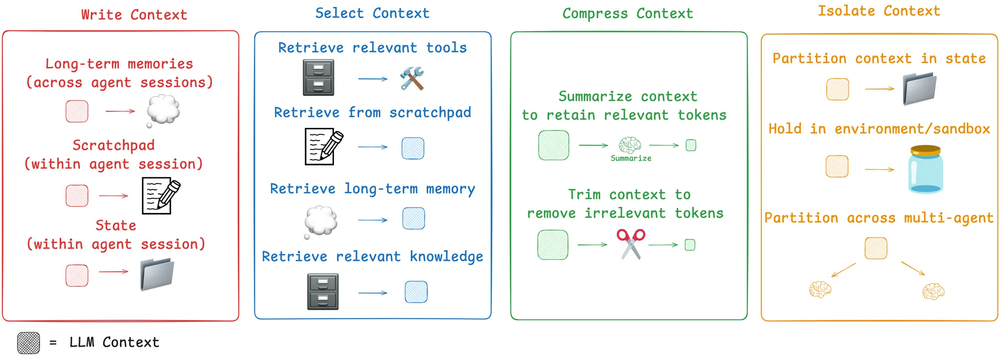
上下文工程的通用类别
上下文工程
正如 Andrej Karpathy 所说,大型语言模型(LLMs)就像一种新型的操作系统。LLM 就像是 CPU,而它的上下文窗口则如同 RAM,充当模型的工作记忆。就像 RAM 一样,LLM 的上下文窗口在处理各种上下文来源时容量有限。正如操作系统会精心管理哪些内容能放入 CPU 的 RAM 中一样,我们可以认为“上下文工程”扮演着类似的角色。Karpathy 对此总结得很好:
[上下文工程是]“……一门精巧的艺术与科学,旨在为下一步操作精准地填充上下文窗口所需的信息。”
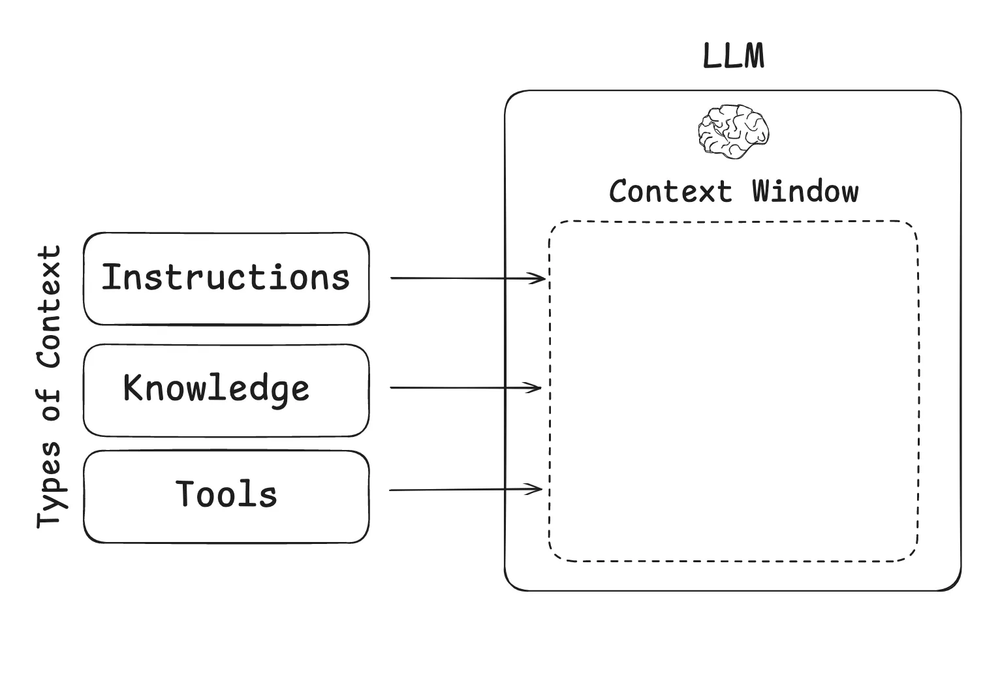
在 LLM 应用中常用的上下文类型
在构建 LLM 应用时,我们需要管理哪些类型的上下文?上下文工程作为一个总括性的概念,适用于几种不同的上下文类型:
- 指令 (Instructions) – 提示(prompts)、记忆(memories)、少样本示例(few-shot examples)、工具描述等。
- 知识 (Knowledge) – 事实、记忆等。
- 工具 (Tools) – 来自工具调用的反馈。
面向智能体的上下文工程
今年,随着 LLM 在推理和工具调用方面的能力越来越强,人们对智能体的兴趣大增。智能体通常为了执行长期任务而交替进行 LLM 调用和工具调用。它们利用工具的反馈来决定下一步行动。
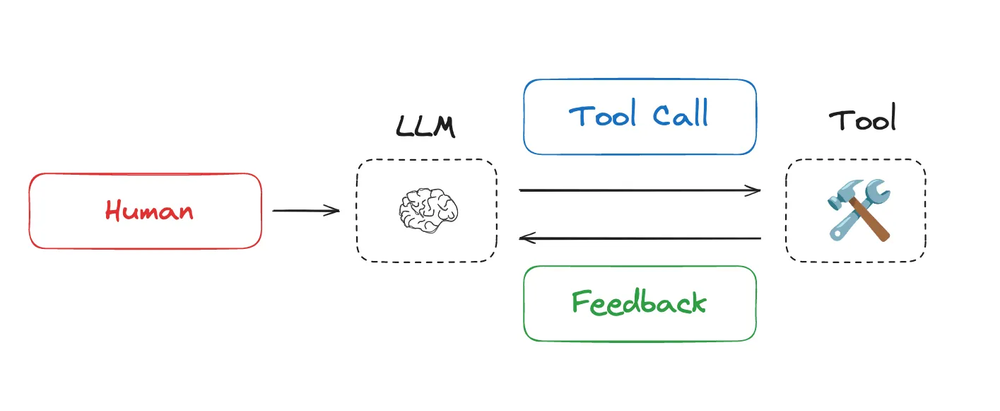
智能体交替执行LLM调用和工具调用,利用工具反馈来决定下一步行动
然而,长期运行的任务和来自工具调用的累积反馈意味着智能体通常会使用大量的 token。这可能导致诸多问题:超出上下文窗口大小、成本/延迟激增,或降低智能体性能。Drew Breunig 很好地概述了更长的上下文可能导致性能问题的几种具体方式,包括:
- 上下文中毒 (Context Poisoning): 当幻觉(hallucination)进入上下文时。
- 上下文分心 (Context Distraction): 当上下文信息淹没了训练目标时。
- 上下文混淆 (Context Confusion): 当多余的上下文影响响应时。
- 上下文冲突 (Context Clash): 当上下文的某些部分相互矛盾时。
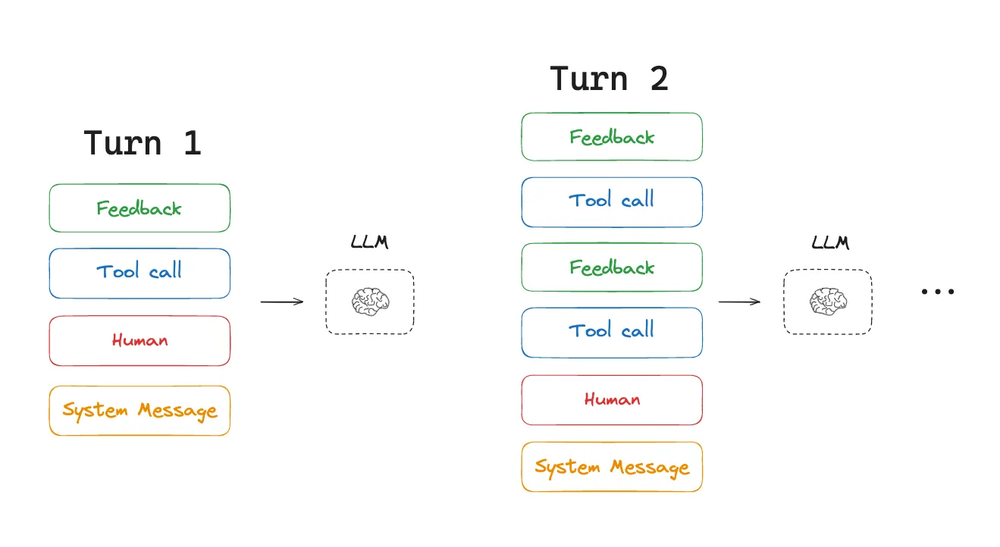
来自工具调用的上下文会在多个智能体回合中累积
考虑到这一点,Cognition 公司指出了上下文工程的重要性:
“上下文工程”……实际上是构建 AI 智能体的工程师的首要工作。
Anthropic 公司也清楚地说明了这一点:
智能体通常会进行长达数百回合的对话,这需要精心的上下文管理策略。
那么,如今人们是如何应对这一挑战的呢?我们将常见的智能体上下文工程策略分为四个类别——写入(write)、选择(select)、压缩(compress)和隔离(isolate)——并通过回顾一些流行的智能体产品和论文来给出每个类别的示例。然后,我们将解释 LangGraph 是如何被设计来支持它们的!
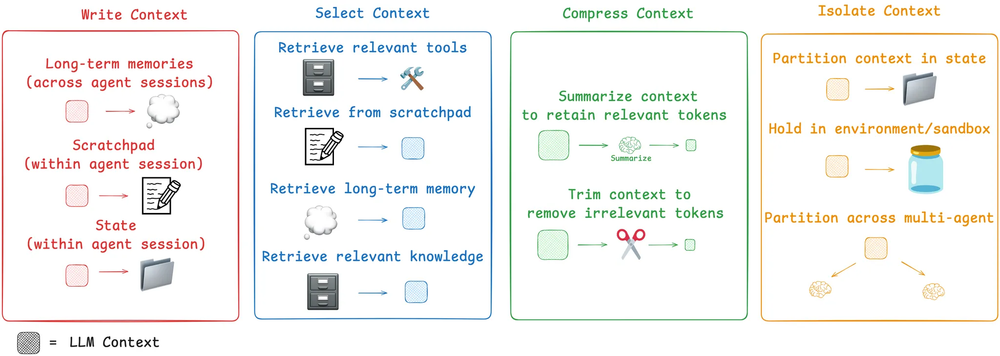
写入上下文 (Write Context)
写入上下文意味着将其保存在上下文窗口之外,以帮助智能体执行任务。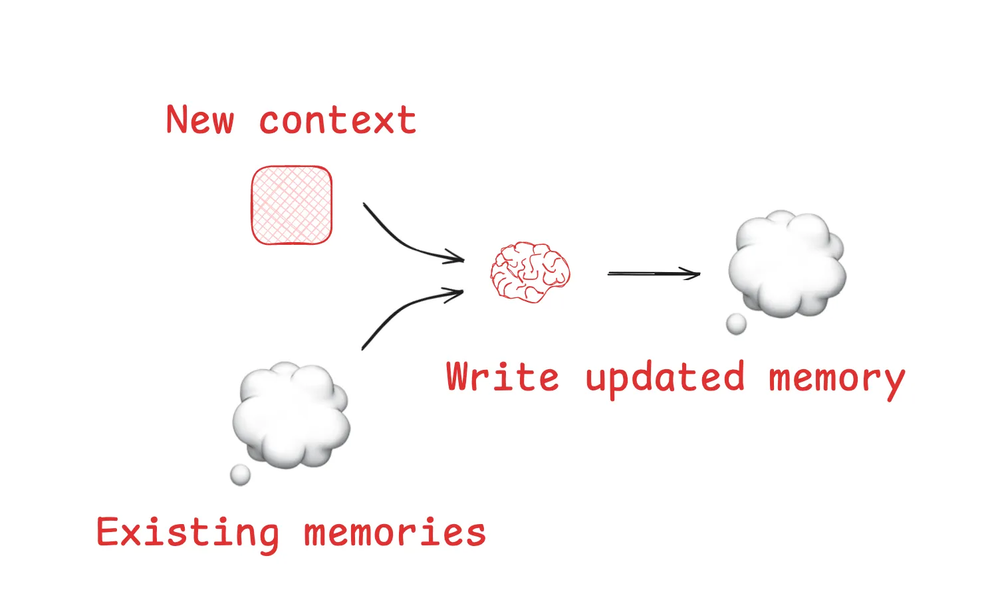
便签 (Scratchpads)
当人类解决任务时,我们会做笔记并为未来相关的任务记住一些事情。智能体也正在获得这些能力!通过“便签”做笔记是一种在智能体执行任务时持久化信息的方法。其思想是将信息保存在上下文窗口之外,以便智能体随时取用。Anthropic 的多智能体研究员给出了一个清晰的例子:
首席研究员(LeadResearcher)首先思考方法,并将其计划保存到记忆(Memory)中以持久化上下文,因为如果上下文窗口超过 200,000 个 token,它将被截断,而保留计划至关重要。
便签可以通过几种不同的方式实现。它们可以是一个简单地将内容写入文件的工具调用,也可以是会话期间持久存在的运行时状态对象中的一个字段。无论哪种方式,便签都让智能体能够保存有用的信息以帮助它们完成任务。
记忆 (Memories)
便签帮助智能体在给定的会话(或线程)内解决任务,但有时智能体需要跨多个会话记住事情才能受益!Reflexion 这篇论文引入了在每个智能体回合后进行反思并重用这些自生成记忆的思想。Generative Agents 则创建了从过去智能体反馈集合中周期性合成的记忆。
一个LLM可以被用来更新或创建记忆
这些概念已经进入了像 ChatGPT、Cursor 和 Windsurf 这样的流行产品中,它们都有基于用户与智能体交互来自动生成可跨会话持久化的长期记忆的机制。
选择上下文 (Select Context)
选择上下文意味着将其拉入上下文窗口以帮助智能体执行任务。
便签 (Scratchpad)
从便签中选择上下文的机制取决于便签的实现方式。如果它是一个工具,那么智能体只需进行一次工具调用即可读取它。如果它是智能体运行时状态的一部分,那么开发者可以选择在每一步向智能体暴露状态的哪些部分。这为在后续回合中向 LLM 暴露便签上下文提供了细粒度的控制。
记忆 (Memories)
如果智能体有能力保存记忆,它们也需要有能力选择与当前执行任务相关的记忆。这在几个方面很有用。智能体可能会选择少样本示例(情景记忆)作为期望行为的范例,选择指令(程序性记忆)来引导行为,或者选择事实(语义记忆)作为与任务相关的上下文。

确保选择到相关的记忆是一个挑战
一个挑战是确保选择到相关的记忆。一些流行的智能体只是使用一小组总是被拉入上下文的文件。例如,许多代码智能体使用特定文件来保存指令(“程序性”记忆),或者在某些情况下,保存示例(“情景”记忆)。Claude Code 使用 CLAUDE.md。Cursor 和 Windsurf 使用规则文件。
但是,如果一个智能体存储了大量的 حقایق 和/或 关系(例如,语义记忆),选择就变得更加困难。ChatGPT 是一个很好的例子,它是一个存储并从大量用户特定记忆中进行选择的流行产品。
用于记忆索引的嵌入(Embeddings)和/或知识图谱是常用的辅助选择技术。尽管如此,记忆选择仍然具有挑战性。在 AIEngineer 世界博览会上,Simon Willison 分享了一个选择出错的例子:ChatGPT 从记忆中获取了他的位置,并意外地将其注入到一张被请求的图片中。这种意外或不希望的记忆检索会让一些用户感觉上下文窗口“不再属于他们了”!
工具 (Tools)
智能体使用工具,但如果提供的工具过多,它们可能会不堪重负。这通常是因为工具描述重叠,导致模型对使用哪个工具感到困惑。一种方法是对工具描述应用 RAG(检索增强生成),以便只为任务获取最相关的工具。最近的一些论文表明,这可以将工具选择的准确性提高 3 倍。
知识 (Knowledge)
RAG 是一个内容丰富的话题,它可能是一个核心的上下文工程挑战。代码智能体是 RAG 在大规模生产中的最佳范例之一。来自 Windsurf 的 Varun 很好地抓住了其中一些挑战:
索引代码 ≠ 上下文检索……[我们正在做] 索引和嵌入搜索……[通过] AST 解析代码并沿语义上有意义的边界进行分块……随着代码库规模的增长,嵌入搜索作为一种检索启发式方法变得不可靠……我们必须依赖多种技术的组合,如 grep/文件搜索、基于知识图谱的检索,以及……一个重排序步骤,其中[上下文]按相关性顺序进行排序。
压缩上下文 (Compressing Context)
压缩上下文涉及仅保留执行任务所需的 token。
上下文总结 (Context Summarization)
智能体交互可能跨越数百个回合,并使用消耗大量 token 的工具调用。总结是管理这些挑战的一种常用方法。如果你用过 Claude Code,你已经见过它的实际应用。当你超过上下文窗口的 95% 时,Claude Code 会运行“自动压缩”,并总结用户与智能体交互的整个轨迹。这种跨智能体轨迹的压缩可以使用各种策略,例如递归或分层总结。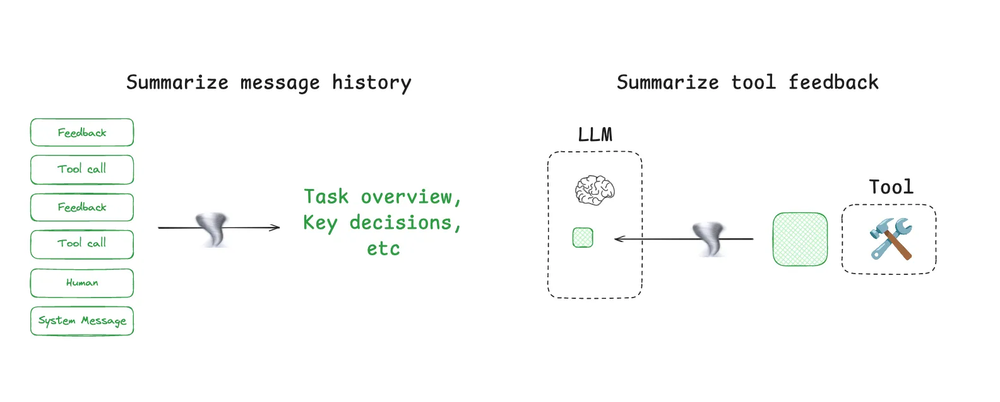
可以应用总结的几个地方
在智能体设计的特定点添加总结也可能很有用。例如,它可以用于后处理某些工具调用(例如,消耗大量 token 的搜索工具)。第二个例子,Cognition 提到了在智能体-智能体边界进行总结,以减少知识交接过程中的 token 消耗。如果需要捕获特定的事件或决策,总结可能是一个挑战。Cognition 为此使用了一个微调模型,这突显了这一步可能需要投入多少工作。
上下文裁剪 (Context Trimming)
总结通常使用 LLM 来提炼上下文中最相关的部分,而裁剪通常可以过滤或如 Drew Breunig 指出的那样,“修剪”上下文。这可以使用硬编码的启发式方法,比如从列表中删除较早的消息。Drew 还提到了 Provence,一个为问答任务训练的上下文修剪器。
隔离上下文 (Isolating Context)
隔离上下文涉及将其分解以帮助智能体执行任务。
多智能体 (Multi-agent)
隔离上下文最流行的方法之一是将其分散到多个子智能体中。OpenAI Swarm 库的一个动机是关注点分离,即一个智能体团队可以处理特定的子任务。每个智能体都有一套特定的工具、指令和自己的上下文窗口。
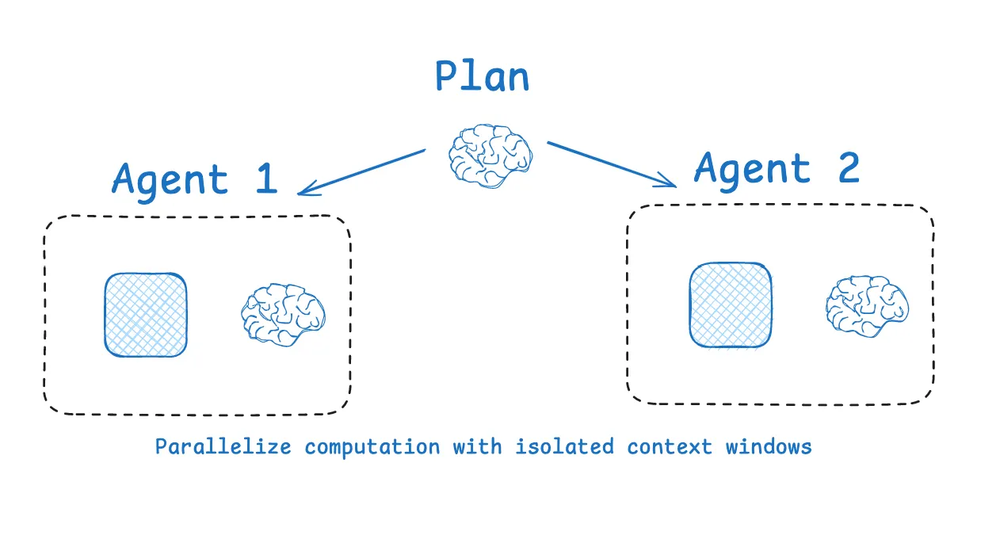
在多个智能体之间分割上下文
Anthropic 的多智能体研究员为此提供了论据:拥有隔离上下文的多个智能体胜过单个智能体,很大程度上是因为每个子智能体的上下文窗口可以分配给更狭窄的子任务。正如该博客所说:
[子智能体] 以其自己的上下文窗口并行操作,同时探索问题的不同方面。
当然,多智能体面临的挑战包括 token 的使用(例如,据 Anthropic 报告,最多比聊天多 15 倍的 token)、需要仔细的提示工程来规划子智能体的工作,以及子智能体之间的协调。
使用环境隔离上下文 (Context Isolation with Environments)
HuggingFace 的深度研究员展示了另一个有趣的上下文隔离示例。大多数智能体使用工具调用 API,这些 API 返回 JSON 对象(工具参数),这些对象可以传递给工具(例如,搜索 API)以获取工具反馈(例如,搜索结果)。HuggingFace 使用一个 CodeAgent,它输出包含所需工具调用的代码。然后,该代码在一个沙盒中运行。从工具调用中选择的上下文(例如,返回值)随后被传回给 LLM。
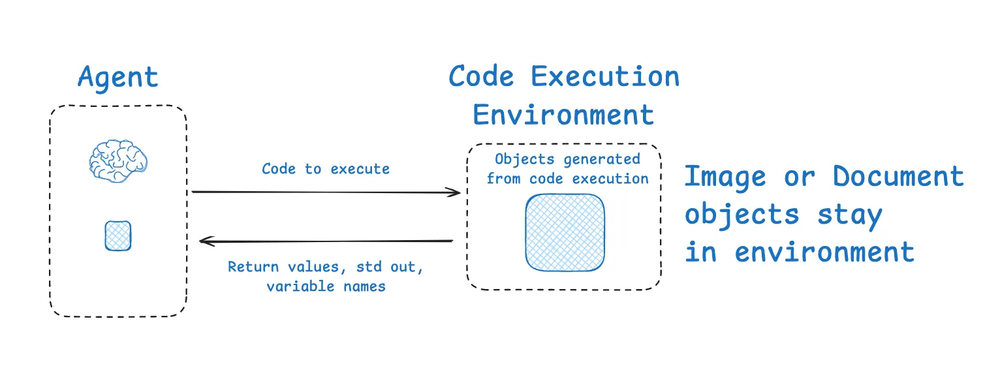
沙盒可以从LLM中隔离上下文
这允许上下文在环境中与 LLM 隔离。Hugging Face 指出,这是一种特别好的隔离消耗大量 token 对象的方式:
[代码智能体允许] 更好地处理状态……需要为以后使用存储这个图像/音频/其他东西吗?没问题,只需在你的状态中将其赋值为一个变量,你就可以[稍后使用它]。
状态 (State)
值得一提的是,智能体的运行时状态对象也是隔离上下文的好方法。这可以起到与沙盒相同的作用。可以设计一个带有字段的模式(schema)的状态对象,上下文可以写入这些字段。模式的一个字段(例如,messages)可以在智能体的每个回合暴露给 LLM,但该模式可以将信息隔离在其他字段中,以供更有选择性地使用。
使用 LangSmith / LangGraph 进行上下文工程
那么,你如何应用这些思想呢?在开始之前,有两个基础部分是很有帮助的。首先,确保你有一种方法来查看你的数据并跟踪智能体中的 token 使用情况。这有助于确定在上下文工程中何处投入精力是最佳的。LangSmith 非常适合智能体追踪/可观察性,并为此提供了一个很好的方式。其次,确保你有一个简单的方法来测试上下文工程是损害还是改善了智能体性能。LangSmith 能够进行智能体评估,以测试任何上下文工程努力的影响。
写入上下文 (Write context)
LangGraph 的设计同时考虑了线程范围(短期)和长期记忆。短期记忆使用检查点(checkpointing)来持久化智能体在所有步骤中的状态。这作为“便签”非常有用,允许你将信息写入状态并在智能体轨迹的任何步骤中获取它。
LangGraph 的长期记忆让你可以在与智能体的多个会话中持久化上下文。它很灵活,允许你保存小文件集(例如,用户配置文件或规则)或更大的记忆集合。此外,LangMem 提供了一套广泛有用的抽象,以帮助进行 LangGraph 的记忆管理。
选择上下文 (Select context)
在 LangGraph 智能体的每个节点(步骤)内,你可以获取状态。这使你能够细粒度地控制在每个智能体步骤向 LLM 呈现什么上下文。
此外,LangGraph 的长期记忆在每个节点内都可访问,并支持各种类型的检索(例如,获取文件以及对记忆集合进行基于嵌入的检索)。有关长期记忆的概述,请参阅我们的 Deeplearning.ai 课程。有关应用于特定智能体的记忆的入门知识,请参阅我们的 Ambient Agents 课程。该课程展示了如何在能够管理你的电子邮件并从你的反馈中学习的长期运行智能体中使用 LangGraph 记忆。
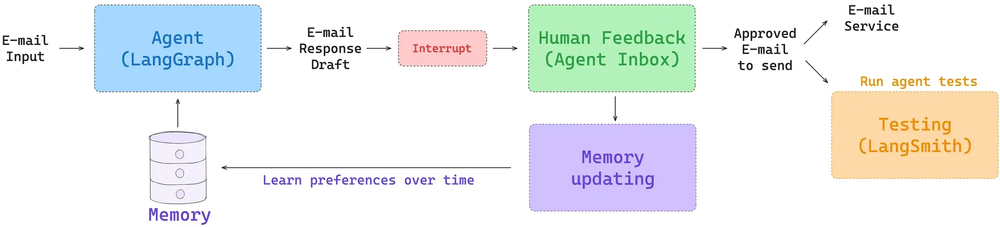
带有用户反馈和长期记忆的电子邮件智能体
对于工具选择,LangGraph Bigtool 库是对工具描述应用语义搜索的好方法。这有助于在处理大量工具时为任务选择最相关的工具。最后,我们有几个教程和视频展示了如何将各种类型的 RAG 与 LangGraph 结合使用。
压缩上下文 (Compressing context)
因为 LangGraph 是一个低级别的编排框架,你可以将你的智能体布局为一组节点,定义每个节点内的逻辑,并定义一个在它们之间传递的状态对象。这种控制提供了几种压缩上下文的方法。
一种常见的方法是使用消息列表作为你的智能体状态,并使用一些内置的实用工具定期对其进行总结或裁剪。然而,你也可以通过几种不同的方式添加逻辑来后处理工具调用或智能体的工作阶段。你可以在特定点添加总结节点,或者在你的工具调用节点中添加总结逻辑,以压缩特定工具调用的输出。
隔离上下文 (Isolating context)
LangGraph 是围绕一个状态对象设计的,允许你指定一个状态模式并在每个智能体步骤访问状态。例如,你可以将来自工具调用的上下文存储在状态的某些字段中,将它们与 LLM 隔离,直到需要该上下文。除了状态,LangGraph 还支持使用沙盒进行上下文隔离。请参阅此 repo 以获取一个使用 E2B 沙盒进行工具调用的 LangGraph 智能体示例。请参阅此视频以获取一个使用 Pyodide 进行沙盒处理的示例,其中状态可以被持久化。LangGraph 还对构建多智能体架构有很多支持,例如 supervisor 和 swarm 库。你可以观看这些视频以获取有关将多智能体与 LangGraph 结合使用的更多详细信息。
结论 (Conclusion)
上下文工程正在成为智能体构建者应该力求掌握的一门技艺。在这里,我们介绍了一些在当今许多流行智能体中看到的常见模式:
- 写入上下文 – 将其保存在上下文窗口之外,以帮助智能体执行任务。
- 选择上下文 – 将其拉入上下文窗口,以帮助智能体执行任务。
- 压缩上下文 – 仅保留执行任务所需的 token。
- 隔离上下文 – 将其分解,以帮助智能体执行任务。
LangGraph 使得实现它们中的每一个都变得容易,而 LangSmith 提供了一种简单的方法来测试你的智能体并跟踪上下文使用情况。LangGraph 和 LangSmith 共同构成了一个良性反馈循环,用于识别应用上下文工程的最佳机会、实施它、测试它,并重复此过程。