一、简介
LLaMA是2023年Meta发布的基础LLM模型,该模型有四个版本,分别是7B、13B、33B、65B参数的模型。最近因为模型被泄漏,模型权重可以在网上搜索下载。相对于GPT序列的模型,LLaMA更加亲民一些,主要体现在参数量较小的模型也可以让平民玩的动。而且现在网上有不少基于LLaMA模型做的应用,比如ChatDoctor、Alpaca等等。
二、主要贡献
1、小模型在大Token size训练长时间,效果可以取得不错的性能,而且推理速度也会变快。
2、开源整个模型,并且可以商用。
三、训练数据集
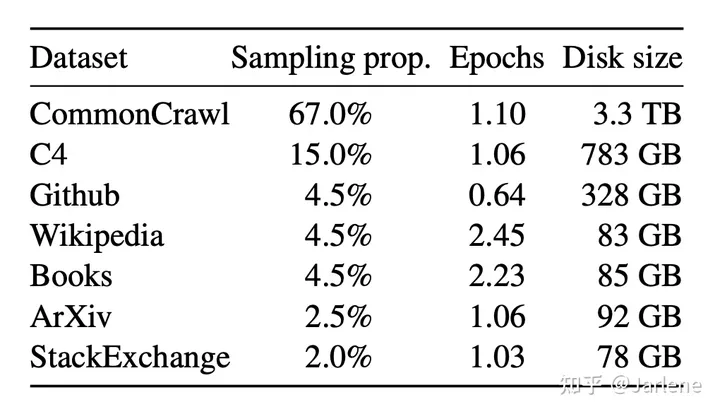
LLaMA使用的都是公开的数据集,这点和Chinchilla, PaLM, GPT-3 等模型不同,包含了未公开的数据集,因此在某些领域LLaMA可能不如包含了Chinchilla, PaLM, GPT-3这类模型。也因此在开源使用上,就不存在侵权的可能。以下图片是LLaMA训练使用到的数据集情况。
四、模型架构
模型训练
论文提到模型训练采用是和GPT序列类似的方法。但是做了以下几点修改:
- Pre-normalization:每一个Transformer sub-layer输入之前都有一个Norm,在GPT3中LayerNorm,而LLaMA使用的RMSNorm,RMSNorm是 LayerNorm的简化,假设均值为0。 gi是一个可学习的参数。

- Tokenizer:使用的 byte- pair encoding (BPE) 。这个其实是一个数据压缩算法,BPE 确保最常见的词在词汇表中表示为单个标记,而稀有词被分解为两个或更多子词标记,这与基于子词的标记化算法所做的一致 。具体举个例子。具体的一些算法原理参考Byte-Pair Encoding: Subword-based tokenization | Towards Data Science
原始数据:aaabdaaabac 假设aa两个字母经常出现,则Z=aa, 原始数据转化为:ZabdZabac。 在假设ab两字母也比较常见,则Y=ab, 那么则可以继续转换为:ZYdZYac
- SwiGLU激活:这个和PaLM类似,详细参考PaLM语言模型论文讲解。
- Rotary Embeddings:引入RoPE,这个也和PaLM类似,详细参考PaLM语言模型论文讲解。
- AdamW 优化器: β1 = 0.9, β2 = 0.95。
- learning rate schedule:使用的cos函数。 final learning rate = 0.1 * maximal learning rate。
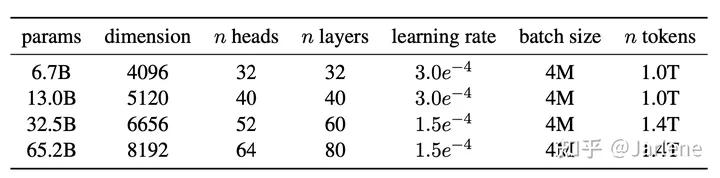
其他的相关参数参考
训练加速器
LLaMA模型训练有两个加速操作:
- 使用causal multi-head attention:减少内存使用和计算量。主要是通过不存储注意力权重和不计算key, query score来实现的。有兴趣可以参考下面两篇文章
SELF-ATTENTION DOES NOT NEED MEMORYarxiv.org/pdf/2112.05682.pdf
FlashAttentionarxiv.org/pdf/2205.14135.pdf
- 反向传播的时候大量减少激活函数计算:提前保存计算比较贵的激活函数的输出结果。这个实现的方式是人工实现transformer layer的反向传播,而不是使用autograd。为了减少内存使用,需要使用model and sequence parallelism来训练。
文章提到,训练65B的模型使用2048块A100 80G的GPU,训练21天左右。可见这个成本还是非常高的。
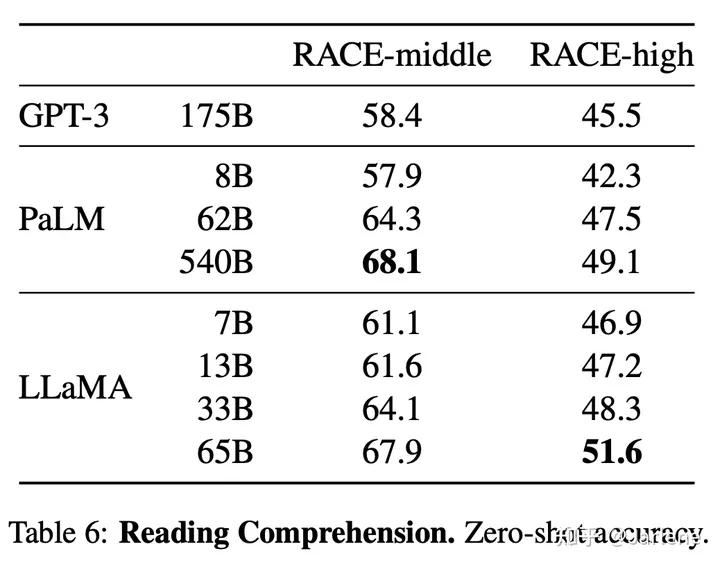
五、实验
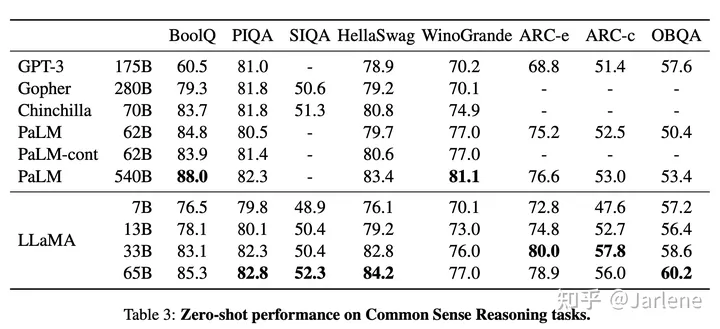
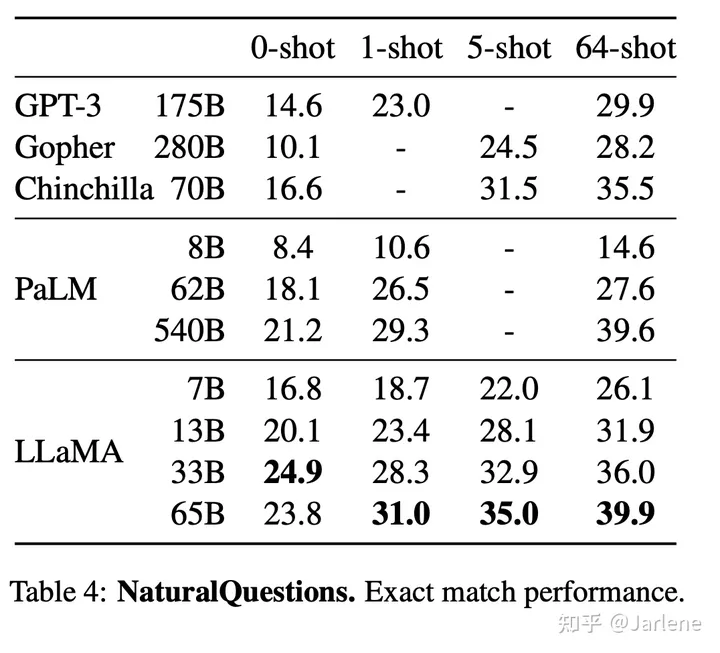
实验取得不错的效果,在多个数据集上都取得了比较不多的实验成绩。尤其7B的模型,有些赎回基金都可以达到GPT-3的模型效果。
总结
LLaMA模型完全的开源,使得研究者可以基于此开发较多下游应用,同时因为小模型(7B、13B)模型效果都表现不错,使得它在没有大量计算资源的情况也可以做了一下研究。这个相对GPT序列来说,非常亲民的。
参考资料: