1. 简介
在前面一章我们已经介绍过文本生成任务中非常流行的一种模型结构,encoder-decoder,但是除此之外,还存在其他一些不一样的模型结构。本文主要介绍另外一种模型结构,因果语言模型。因果语言模型(causal language model),是跟掩码语言模型相对的语言模型,跟transformer机制中的decoder很相似,因果语言模型采用了对角掩蔽矩阵,使得每个token只能看到在它之前的token信息,而看不到在它之后的token,模型的训练目标是根据在这之前的token来预测下一个位置的token。通常是根据概率分布来计算词之间组合的出现概率,因果语言模型根据所有之前的token信息来预测当前时刻token,所以可以很直接地应用到文本生成任务中。可以理解为encoder-decoder的模型结果使用了完整的transformer结构,但是因果语言模型则只用到transformer的decoder结构(同时去掉transformer中间的encoder-decoder attention,因为没有encoder的结构)。
虽然因果语言模型结构简单而且对于文本生成来说直截了当,但是它本身还是带有一些结构或者算法上的限制。首先因果语言模型都是从左往右对token依次进行编码,忽略了相应的双向信息。其次,因果语言模型不适合处理部分端到端的任务,在包括摘要和翻译等任务中不能取得令人满意的结果。
2. 英文预训练语言模型
2.1 GPT
GPT是第一个应用到文本生成任务中的深度预训练语言模型,验证了语言模型在各种各样无标注数据上进行预训练的有效性。不同于Bert是由多个transformer的encoder堆叠形成,GPT则是由transformer的多个decoder堆叠产生。
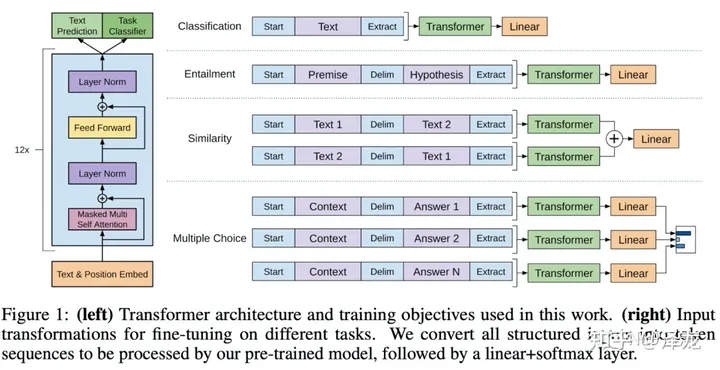
GPT的训练过程分为两个阶段,第一阶段是无监督预训练,主要是从大量无标注的语料中学习通用的语言模型的能力,目标函数如下图,基于前几个token来预测当前token,训练目标是最大化相应的似然函数。相应的条件概率计算可以通过神经网络计算得到,最终每个位置每个token的出现概率通过将transformer最后一层的隐状态加上一层全连接层然后通过softmax归一化计算得到。
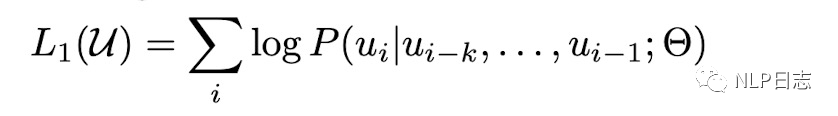
第二个阶段是有监督微调,这个阶段的目标函数包括两部分,一部分还是第一阶段的语言模型目标函数,另一个部分是具体下游任务的目标函数,对于每个有标注的文本,都一个相应的label,将GPT中最后一个transformer的隐状态加上一层全连接层+softmax归一化可以计算得到相应的概率(不同的下游任务对应不同的全连接层),将这部分作为下游任务的目标函数,希望这部分的取值极可能大。
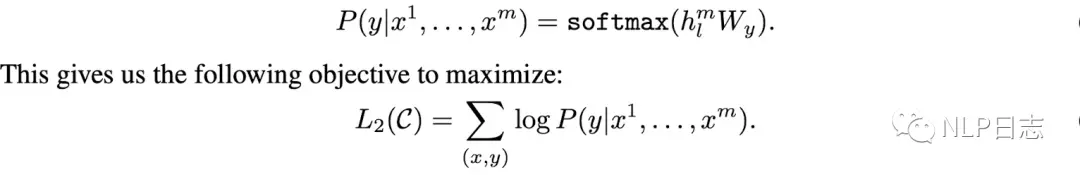
然后将这两部分目标函数加权得到最终的目标函数。
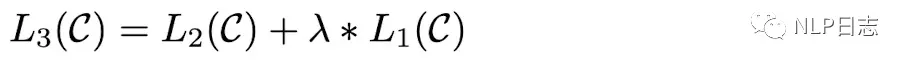
2.2 GPT-2
GPT-2对语言模型在zero-shot生成任务下的迁移能力进行探索,验证了充足数据的明显意义。GPT-2沿用了GPT的单向语言模型结构,同时也有一些新的变化。
a). 去掉finetune层,对于不同的下游任务,GPT会在transformer后面接相应的全连接层,GPT-2不同的任务采用同一个模型,不再需要一个特定任务的finetune层,只是在输入时加入相应的任务提示,跟当下火热的prompt如出一辙。
b). 训练时使用更多数据集
c). 增大模型参数,GPT的模型包含12层堆叠的transformer的decoder,而GPT-2的网络更深,最多有48层。
d). 调整Layer normalization顺序,以前的transformer的layer normalization都是在各个子模块后面的,GPT-2将layer normalization层放置到各个子模块前面。并且在最后一个self attention后新增加了一层layer normalization。
e). 采用了BPE编码,词汇表增加到50257,上下文长度从512增加到1024,训练时使用更大的batch size(512)。
整体来说,模型结构上的创新相对于GPT没有太大变化,更多的是变大变强了,在下游任务的效果都有明显的提升,进一步验证了大力出奇迹的理念。后续的GPT-3在更大更强的道路上愈走愈远,验证了通过少数的样例或者模版,更大的模型可以明显提高下游生成任务的效果。不仅在多个自然语言理解任务上达到SOTA的效果,在文本生成任务上也取得惊人的效果。
2.3 CTRL
回想下GPT系列的模型,模型的参数庞大,在文本生成上表现惊人,但是GPT系列模型生成的风格和内容都是由模型自身学习得到的(从大量训练语料中学习),并不可控。而CTRL则是通过引入控制代码(control code)来管理风格,内容和特定任务行为从而生成相对可控的文本。




CTRL依旧是由多个transformer堆叠产生的,在计算attention的过程中由于mask矩阵的存在,其实也相当于多个decoder的相互叠加,但是它的输入跟之前的模型不同,CTRL将控制代码(control code)置于文本前面,一同作为模型的输入。在预测下个位置token的时候会生成相应的各个token的得分,选取其中得分最高前k个,根据下面的公式计算得到相应token的概率,
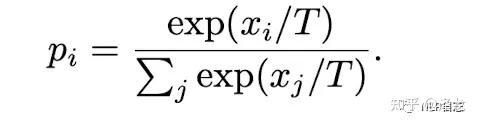
再根据随机采样从多元正态分布中选取一个下一个位置的预测值。其中当T趋近了于0 时会类似于贪婪分布,放大了峰值,会更倾向于得分最高的token。当T趋近于无穷时分布会更加平坦,各个token被选中的概率更加接近。同时需要注意上面的k并不是固定不变的,而是自适应的,如果下一个token的概率比较高,相应的k就比较小,反之则比较大。另外在推理时,为了避免生成大量重复token,在计算概率时引进了一个惩罚项,当某个token已经存在于之前的生成文本时,再次计算概率时会降低相应的概率值。
3. 中文预训练语言模型
3.1 CPM
前面几种文本生成的方法都是针对英文语料训练的,CPM则是当时发布的最大的一个中文预训练语言模型。CPM同样是由transformer的decoder组成,模型本身没有太大的变化,但是有几个需要注意的地方。
a). 词表不同,以往的中文预训练模型的词表都是以字为单位构建的,这样会导致部分词的语义不完整,为了解决这个问题,CPM构建了一个新的由字跟词混合得到的词表,加入了常用的词。
b). 训练策略不同,中文词的分布的稀疏性比起英文更加严重,为了解决这个问题,CPM在训练时采用了更大的batch size来保证模型训练更加稳定(GPT-3的一个batch size有1百万个token,而CPM一个batch size有3百万个token)。
3.2 PanGu-
PanGu- 同样是一个中文预训练语言模型,模型结构也基本沿用transformer的decoder,除此之外,在最后一层transformer层后,它构建一个query层,用于显示推断期望得到的输出。
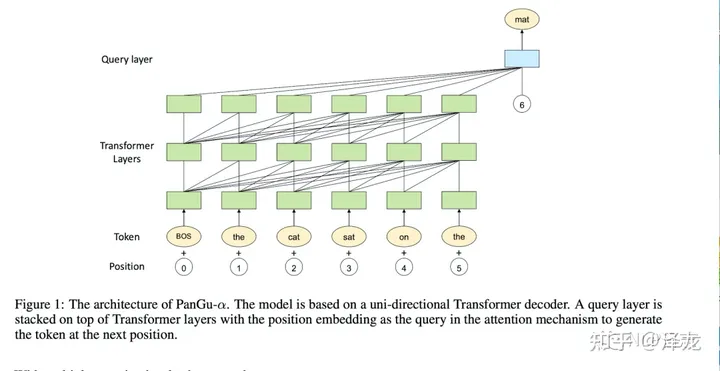
Query层的结构跟transformer的decoder相似,除了计算query跟key时点积做了调整外其余的attention计算跟ffn都保持一致,其中p_n是一个额外的词嵌入,代表下一个位置的信息。
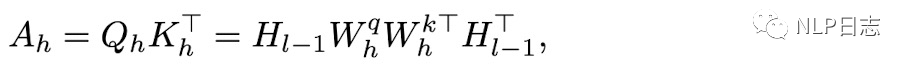
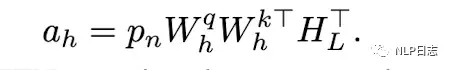
4. 总结
在文本生成任务中,可以看到因果语言模型基本沿用的都是transformer的decoder结构,在模型上没有太多的变化,无论是中文上的还是英文上,从另一方面也能说明transformer的优越性。同时,整个发展历史上基本都是围绕着使用更多的训练数据和构建更大的模型展开,大力出奇迹。
参考资料:https://zhuanlan.zhihu.com/p/464546351