如果是主节点与集群失联
1.剩下的节点会进行主节点选举,此过程可能会发生脑裂。
2.并将主节点上的主分片对应的在其他节点上的副本分片提升为主分片。
3.在副本分片被提拔为主分片后,master节点开始执行恢复操作来重建缺失的副本:集群中的节点相互拷贝分片数据。
4.为了达到集群中分片分布的平衡状态,还会发生分片的移动。
但当失联的节点恢复与集群的联系后,这个失联节点将被告知它携带的数据已经没有用,数据已经在其他节点上重新分配了,此时这个失联的节点会把本地的数据删除,为了让集群中的分片分布平衡,又会进行一些分片的移动到此节点上来。
如果这个节点只是短暂的断开,那这些步骤可能会是一些无用功,可已通过设置推迟分片的分配,在集群重新分配之前去检测失联的节点是否已重新加入集群。
PUT /_all/_settings
{
"settings": {
"index.unassigned.node_left.delayed_timeout": "5m"
}
}
但延迟分配并不会阻止副本分片提升为主分片。因为集群需要保证所有的主分片正常,使集群维持在yellow可用状态。缺失副本的重建是唯一延迟的过程。

如果失联节点在此参数设置的时间之后连接上了集群,此时没有完成分片的移动,ElasticSearch会检查当前节点的数据和它对应的主分片的数据是否保持一致,说明在这段时间并没有文档的修改,那么他会取消正在进行的平衡移动,并还原已经移动的数据。
什么是脑裂?
假设现有两个节点组成的集群。
节点一在启动时被选为主节点并保存了主分片,节点二保存主分片的副本分片。
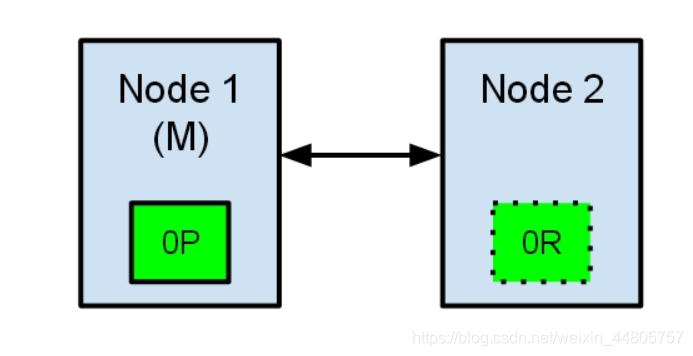
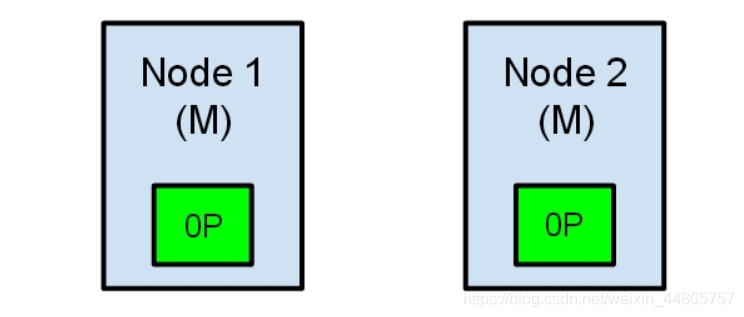
现在由于网络故障导致一个集群被划分成了两片,节点二现在发现集群中没有主节点就会自动将自身提升为主节点。由于主节点被认为是集群的最高统治者,它决定了什么时候创建新的索引,分片的移动等等。那么现在就会出现一个集群中出现两个主节点的情况,数据的完整性将得不到保证。
如何避免脑裂的问题的出现:
elasticsearch的config文件夹中的application.yml中有一个这样的配置
discovery.zen.minimum_master_nodes 这个配置告诉elasticsearch当没有足够的master候选节点时,就不要进行master节点选举,等master候选节点足够了才进行选举。此设置应该始终被配置为master候选节点的法定个数。
比如之前的例子 将此参数设置为discovery.zen.minimum_master_nodes:2,会通过(候选节点数/2+1)=法定数,这个法定数就是在节点间发生通讯故障后,需要有这个数量的候选节点才会进行选举。例如之间的例子,两个节点通讯失败,通过算法(2/2+1)=2,但是现在只有节点二这一个节点,就不会通过选举产生新的master节点,这样杜绝了脑裂的发生,但是同时也让集群的高可用失效。所以一般在生产环境中最少设置3个节点作为一个集群,这样可以设置discovery.zen.minimum_master_nodes:2,(3/2+1)=2,即使主节点出现故障,其他候选节点也满足master选举的条件。
例如:
如果有10个节点(能保存数据,同时能成为master),法定数就是(10/2+1)=6。
如果有3个候选master节点,和100个data节点,法定数就是(3/2+1)=2。
参考资料:
https://www.elastic.co/guide/en/elasticsearch/reference/current/delayed-allocation.html
https://www.elastic.co/guide/cn/elasticsearch/guide/current/_delaying_shard_allocation.html
引自:https://blog.csdn.net/weixin_44805757/article/details/115213670